Реактивни системи
През януари заедно с dev.bg решихме да стартираме група, в която всеки месец да дискутираме някои интересни технологични теми, за които, може би поради тяхната сложност и обхват, не се говори достатъчно в България. Такива са например:
- Функционално програмиране и функционални абстракции;
- Разпределени системи;
- Конкурентност и конкурентни модели;
- Управление на събития;
- Асинхронни съобщения, messaging технологии и потоци от данни;
- Устойчивост и толерантност към грешки;
- Domain-Driven Design;
- Консистентност и различни подходи за съхранение на данни;
- Дизайн и архитектура на съвременни системи.
Дълбокото им изучаване е трудно, но дори общи познания по тях могат да са много полезни и обогатяващи за работа на всеки един програмист и могат да го накарат да преосмисли и опрости разбиранията си за софтуерните системи. На пръв поглед темите са доста разнообразни, но всъщност, когато ги разглеждаме в светлината на изграждането на един тип системи, те взаимно се допълват. Тези системи се характеризират с едно общо свойство, което ги обединява и на което кръстихме групата – реактивност.
В тази статия ще разгледаме какво е „реактивна система“, защо това понятие е релевантно към всекидневната ни работа като програмисти и ще опитаме да вникнем по-надълбоко в неговото значение и по какъв начин то е свързано с гореизброените технологични проблеми. Статията се базира на уводната лекция в групата.
1. Значение на реактивността
Често за да вникнем в същността на даден термин се оказва най-добре да погледнем в тълковния речник. Ето какво казва Оксфордският речник за „reactive“:
- Showing a response to a stimulus.
- Acting in response to a situation rather than creating or controlling it.
или в превод, реактивно е нещо, което:
- откликва/отговаря на стимул;
- действа в отговор на ситуация, а не я създава или контролира.
По този начин дефинираме и понятието реактивни системи – системи, които откликват (реагират) на стимули от външния свят и които не са в контрол, а биват контролирани от външния свят. На тази дефиниция се базира публикацията „On Development of Reactive Systems“ на Дейвид Харел и Амир Пнуели [1], която първа използва термина в контекста на софтуерни системи. Тя разглежда дихотомията на трансформиращите и реактивните системи като фундаментално разграничение между системи, които са относително лесни за разработка, и такива, които не са.
Трансформиращите системи приемат вход, трансформират го и генерират резултат. Това са както системите, работещи с предварително зададен вход – например инструменти, трансформиращи и обработващи файлове или подадени им входни аргументи, които приключват след края на изчислението – така и интерактивните системи, които, когато решат, изискват допълнителен вход от потребителя. Характерното за трансформиращите системи е, че те са изцяло в контрол на програмния поток и не откликват на действия от външния свят, освен когато изрично изискват конкретен вход от него (при което те паузират изпълнението си докато го чакат). Това са именно програмите, които повечето от нас са писали когато сме се учили да програмираме.
Реактивните системи, по дефиницията, която дадохме, са точно противоположното – те поддържат непрекъснато взаимодействия с външния свят и биват контролирани от него. Това са по-голямата част от софтуерните приложения, които познаваме в днешно време – приложения с потребителски интерфейс, откликващи на натискане на бутони или преместване на мишката, но и системи, реагиращи на получени данни по мрежата, на изминалото време или на повреди, като изваден мрежов кабел или загубило се съобщение. Харел и Пнуели не се ограничават до софтуера, ами разглеждат и физически реактивни устройства, каквито са например различните електрически уреди, контролирани от бутони, часовниците или устройствата, реагиращи на промяната на околната температура.
Реактивните системи всъщност са навсякъде около нас. Защо тогава ги третираме като толкова специални? Разбира се, има причина този термин да е толкова популярен в последните години, въпреки своето общо значение. По своята природа реактивните системи се занимават с асинхронност, конкурентност, недетерминизъм, дистрибутираност, реалновремеви обработки – характеристики, които са поначално смятани за трудни в програмирането. Всички те се развиват във и зависят от времето. Трансформиращите системи от своя страна са добре изучени – те са предмет на ламбда смятането, машината на Тюринг, структурното програмиране и много други модели, принципи и теории в програмирането. По своята дефиниция те не зависят от времето, а единствено от входните данни. Познаваме ги добре и знаем как да ги композираме и как да разбиваме проблемите, които решават, на подпроблеми. При реактивните системи това не е така – все още не сме съвсем сигурни как да ги композираме и декомпозираме. Те със сигурност включват в себе си множество трансформиращи компоненти, но се състоят и от нещо повече. Харел и Пнуели смятат, че декомпозицията на реактивни системи и компоненти резултира в компоненти, които са реактивни сами по себе си.
Основното свойство на реактивните системи – да откликват на външни стимули – ще наричаме още отзивчивост (responsiveness). То включва в себе си това системата да реагира своевременно, до определено разумно време – всеки потребител би очаквал натискането на бутон да има ефект до милисекунди, а не до минути, в противен случай той би счел, че системата не работи. Целта при моделирането и програмирането на реактивни системи е системата да бъде отзивчива във всеки един момент. Именно в това се провалят повечето приложения, най-вече в случаите на натовареност, неработещи (външни) компоненти, частична повреда в мрежата и др.
Отзивчивостта означава още, че реактивните системи са задвижвани от асинхронни събития (event-driven). Ако се върнем на тяхната декомпозиция, то те биха се декомпозирали до реактивни компоненти, имащи зависимости помежду си, където всяка зависимост на един компонент е външен източник на събития/стимули за него. Получаването на събитие/стимул от външния свят към някой граничен за системата компонент води до генерирането на събития за други компоненти в нея, които от своя страна също биха могли да генерират събития/стимули за трети компоненти и т.н. (евентуално до достигане на други гранични компоненти и осъществяване на връзка обратно към външния свят). Така получаваме поток от събития, или още казано поток от данни (dataflow), който протича в софтуерното приложение.
2. Локални системи
Нека да разгледаме реактивността от гледна точка на програма, изпълняваща се върху един компютър.
Може би най-добрият пример за реактивност са електронните таблици. От една страна техният потребителски интерфейс е типичен пример за взаимодействие с външния свят – потребителят може да въвежда скаларни стойности, формули и текст в различни клетки, да скролира таблицата, да взаимодейства с различните менюта. От друга този потребителски интерфейс предоставя на потребителя си средство за програмиране на таблица от реактивни клетки, която, както един програмен код, може да бъде запазена във файл. Някои от тези клетки съдържат входни скаларни или текстови стойности. Стойността на други се определя по зададена в клетката формула, която може да зависи както от входните клетки, така и от други клетки с формули. Софтуерът за електронни таблици непрекъснато изпълнява тази „програма“ – когато бъде променена някоя от входните клетки, то автоматично се обновява стойността на всички клетки с формула, зависеща от променената клетка или от други клетки с формула, чиято стойност се е променила заради входната клетка. Иначе казано, клетките са реактивни – формулите в тях описват граф от зависимости и всяка промяна на входните данни води до разпространение на тези данни до зависещите от тях компоненти (клетки).
Да съпоставим електронните таблици с една програма, написана на стандартен език за програмиране:
var a = 32
var b = 10
var c = a + b
println(c) // 42
a = 20
println(c) // 42В повечето програмни езици, които познаваме, липсва този реактивен модел, който разгледахме при таблиците. При тях промяната на входната променлива a не води до промяна на стойността на c, въпреки че c ясно е дефинирана като зависеща от a и b.
В език с реактивни променливи вторият println би извел 30 вместо 42. Използването в програмния код на изразни средства от този вид, които образуват поток от данни, реагиращ автоматично на външни събития, и граф на зависимости между елементите на програмата, наричаме реактивно програмиране.
Реактивно програмиране чрез императивни средства
Познатият на всички ни начин за образуване на такива потоци и за постигане на отзивчивост е чрез шаблонът Observer и callback функциите. Всички обаче сме се сблъсквали с тяхната експоненциално нарастваща сложност с увеличаване на техния брой. Според изследване на Adobe 1/3 от кода в техните десктоп приложения е посветен на обработка на събития чрез тези подходи и половината от бъговете в приложенията са в този код [2]. Да разгледаме защо се получава това.
По своята природа шаблонът Observer и callback функциите са императивни и обвързани с изменяемо състояние. Когато получат събитие те се активизират реактивно, след което обаче поемат контрол върху промяна на някое състояние, най-често споделено между observer-а, компонента, който е отговорен за него, и други observer-и, които компонентът е регистрирал. Това създава силна обвързаност (coupling) между всички тези елементи. Понякога проактивно генерират допълнителни събития или дори се обвързват с други компоненти като извикват техен метод със странични ефекти. При по-големи приложения или при невнимателен дизайн всички тези изменения и зависимости стават все по-трудни за проследяване. Така отделните компоненти стават трудни за преизползване, но най-вече трудни за композиране. Други проблеми, които понякога срещаме, са пропуснати събития поради късна регистрация, неотрегистрирани observer-и (водещи до течове в паметта), неочаквана рекурсия или популярното явление callback hell.
Погледнато от друга гледна точка, при такъв дизайн се наблюдават няколко прояви на времето:
- всяка стъпка от императивния поток на програмата (най-вече състоянието на променливите в нея) зависи от всички предишни, образувайки една времева линия. При множествено изчислителни нишки всяка от тях има собствена времева линия, а споделянето на изменяемо състояние между нишките води до преплитане на времевите им линии и нуждата от синхронизация на тези линии;
- асинхронните събития от външния свят естествено се случват във времето;
- понякога има значение редът и точният момент на регистрация.
Нужно е да поемем контрол върху времето и да ограничим неговото влияние върху нашите програми. От изброените точки единствено външният свят е отвъд нашия контрол.

…And then one day you find ten years have got behind you
No one told you when to run, you missed the starting gun…
Реактивно програмиране чрез функционални средства
Един от най-мощните методи за справяне с другите две точки и за огъване на времето е функционалното програмиране.
Функционалните програми и компоненти ограничават изменяемостта и страничните ефекти до няколко контролирани места, обикновено до връзката им с външния свят. Целият останал код се състои от чисти математически функции, които нямат (наблюдаеми) странични ефекти и работят единствено с неизменяеми данни, или още казано работят върху снимка на времето. Функционалното програмиране предоставя прост и ефективен метод за декларативно дефиниране на зависимости – изразите. Тъй като нито резултатът от израза нито неговите операнди могат да бъдат промени, то всеки израз директно описва какви са зависимостите на своя резултат. Нещо повече – всяка декларация може да бъде преместена преди друга, стига да няма зависимост между двете (а в езици с lazy evaluation като Haskell дори това липсва като ограничение). Така функционалните програми не описват стъпки, а описват зависимости, които биват верифицирани по естествен път. Инцидентното постигане на цикличност е невъзможно – за нея се изискват явни изразни средства.
Благодарение на всичко това е изключително лесно да се вземат два или повече функционални компонента и да се направи композиция между тях. Функционалното програмиране отваря път към множество мощни и интересни композиращи се абстракции. Реално неизменяемостта променя начина, по който разсъждаваме за нашите програми, и разкрива огромен свят от възможности. Интересен труд, който разглежда ефектите на неизменяемостта, е публикацията „Immutability Changes Everything“ [3]. Както ще видим по-късно, функционалното програмиране е изключително приложимо и за многонишковите и разпределените системи.
Да разгледаме реактивни изразни средства, които са функционални. Истинската полза от тях би се усетила в по-големи приложения, но са лесни за разбиране дори в малки, каквито са следващите примери.
Elm пример
Първият пример, който ще дадем, са сигналите от езика Elm – Haskell-оподобен език, компилиращ се до JavaScript [4]:
import Graphics.Element exposing (..)
import Graphics.Collage exposing (..)
import Color exposing (..)
import Mouse
import Keyboard
import Time
pentagon = filled blue (ngon 5 50)
dashedCircle = outlined (dashed red) (circle 70)
graphics (r, s) = collage 400 400
[
rotate (degrees (toFloat r)) pentagon,
scale (toFloat s / 100) dashedCircle
]
main = graphics(0, 100)graphics е функция, която композира две други декларации – пентагон и кръг – в една графика, като предоставя възможност за завъртане на пентагона и скалиране на кръга. main е входът на нашата програма – тя изчертава графика на незавъртян пентагон и скалиран кръг. Дотук програмата е напълно статична. Ще опишем реактивно взаимодействие, използвайки сигнали. Всеки сигнал представлява дискретен във времето поток от стойности. (В по-новите версии на Elm сигналите са заменени със CQRS подход – понятие, което ще разгледаме малко по-късно.) Най прост пример за такъв е Mouse.position:
main = Signal.map show Mouse.positionMouse.position сигнализира всяка промяна на позицията на мишката чрез двойка (x, y) Той определя вход от външния свят, на който можем да реагираме. Функцията main в Elm играе ролята на изход към външния свят. Тя може да приема както статична единична стойност, така и, както е в последния пример, сигнал от множество стойности – във всеки момент на екрана ще бъде изобразена последната от тях. Signal.map трансформира потока от позиции към поток от текстовата им репрезентация, използвайки функцията show.
Какво ще стане ако заменим show със graphics? Само чрез тази проста композиция ще получим напълно реактивна графика, променяща се с позицията на мишката:
main = Signal.map graphics Mouse.positionСъщо толкова лесно можем да променим входния сигнал или дори да композираме няколко входни сигнала в един. Следващите примери са съответно за вход от клавиатурата, времето като вход и композиция на времето и позицията на мишката. Интересно е, че когато вземем времето като вход получаваме анимация.
arrowsInput = Signal.foldp
(\arr (x, y) -> (x + arr.x * 10, y + arr.y * 10))
(0, 0)
Keyboard.arrows
main = Signal.map graphics arrowsInputperiod = Signal.map
(\t -> floor (t / 4) % 360)
(Time.every Time.millisecond)
periodPair = Signal.map2 (\x y -> (x, y)) period period
main = Signal.map graphics periodPair...
periodAndMouse = Signal.map2
(\(x1, y1) (x2, y2) -> (x1 + x2, y1 + y2))
periodPair Mouse.position
main = Signal.map graphics periodAndMouseЩе отбележим, че всяка една декларация на променлива/функция може да бъде разменена по произволен начин – редът на декларациите няма значение. Всичко в програмата е съвпкупност от изрази и във вътрешността ѝ напълно липсват странични ефекти – те са изнесени по краищата на програмата.
RxJS пример
Подобни поточни структури съществуват в множество библиотеки. За втория ни пример ще използваме RxJS и неговия Observable. При писането на autocomplete форма има няколко неща, за които трябва да се внимава:
- не искаме да правим заявка към сървъра за всеки въведен символ, а вместо това когато потребителят спре да пише (т.е. при няколко милисекунди неактивност);
- възможно е отговорите от сървъра да дойдат в различен ред от този, в който са били поискани. Трябва да се подсигурим, че показваме резултата, произхождащ от последния въведен термин, а не от някой предишен;
- всяка заявка към сървъра може да даде грешка, с която трябва да се справим;
- за да усложним задачата, нека да добавим и изискването когато потребител бързо въведе и изтрие символ да преизползваме старите резултати.
Имплементирането на всички тези изисквания по императивен начин чрез observer обикновено е трудно. Всяко едно от тях по отделно не представлява голяма сложност, но когато тръгнем да ги композираме (в споделено изменяемо състояние) е доста вероятно първите ни опити да са погрешни и с много „ахааа“ моменти.
Целта на функционалните подходи е да можем да вземем решенията на всеки от тези проблеми и просто да ги композираме по правилен начин:
userInputMap<T>(input$: Observable<string>,
to: string => Observable<T>,
debounceDuration = 400): Observable<T> {
return input$.debounceTime(debounceDuration)
.distinctUntilChanged()
.switchMap(to);
}
this.searchResults$ = userInputMap(this.termInput.valueChanges,
term => searchService.resultsFor(term));Това и прави този код – debounceTime се грижи за точка 1, distinctUntilChanged за 4, а switchMap за 2. switchMap подменя текущия Observable поток с резултата от подаването на текущия термин на функцията to, игнорирайки всички предишни нейни резултати, независимо от това кога те ще дадат стойност. Всяка от функциите връща междинен Observable. (http://rxmarbles.com/ е удобен инструмент за експерементиране с поведението на предоставените от RxJS функции.)
Остава въпросът за справяне с грешки, който вече зависи от дизайна на интерфейса на приложението. При текущата имплементация грешка от някоя активна заявка води до преминаване в състояние на грешка на целия searchResults$ поток, който повече не може да бъде възстановен. В такъв случай на потребителя може да се покаже съобщение за проблема и да бъде помолен да презареди страницата. По-добра алтернатива е да бъде уведомяван за грешка при текущия термин, като при въвеждане на нов да бъде направен опит за нова заявка. Това може да бъде постигнато като преобразуваме Observable-а до успешен резултат new Success(result), ако е дал стойност, или до неуспешен резултат new Failure(error), ако е генерирал грешка – и двата са стойности, а не състояние на потока, както беше досега. Лесно можем да напишем функция, която прави това, и да обвием чрез нея резултатът от resultsFor. Допълнително, добре е да направим няколко опита за повторение на заявката – за целта ни е нужна функция retry, която да добавим към цялата композиция.
Други функционални изразни средства
Потоците от Elm и RxJS имат някои ограничения. Едно от тях е т.нар. glitch при едновременно случващи се събития:
const button = document.getElementById("button");
const clicks = Rx.Observable.fromEvent(button, "click");
const decrement = clicks.scan(acc => acc - 1, 0);
const increment = clicks.scan(acc => acc + 1, 0);
const sum = decrement.combineLatest(increment, (a, b) => a + b);
sum.distinctUntilChanged().subscribe(console.log);increment брои натисканията на бутона, а decrement прави същото, но с отрицателна стойност. Логически тяхната сума винаги е 0 и логването от последния ред би трябвало да се изпълни само в началото и да изведе 0 за sum. Това, което се получава обаче, е че при всяко натискане на бутона се извеждат две стойности: -1 и 0. Причината е, че RxJS не знае за единния източник на събитието и, въпреки че всички трансформации са в един и същи логически момент, те стават последователно, първо изменяйки декрементирането в сумата, а след това и инкрементирането.
Функционално реактивно програмиране (FRP) е модел, който се справя с такива проблеми [5, 6]. Той дефинира две основни абстракции – поведения и събития. Поведенията са клетки, съдържащи стойност във всеки един момент от времето (т.е. математически са функция на времето), а събитията са поток от дискретни стойности, дефинирани за определен момент от времето (математически са списък от двойки (момент, стойност)). При имплементациите на този модел съществува ясно изразено понятие за текущ момент, в който се случва текущото обновяване на поведенията и събитията, което ни позволява да избегнем описаните glitch-ове. Друга важна негова характеристика е, че позволява моделирането на непрекъснати във времето стойности. Прост пример, с малко по-интересен реактивен поток и използващ библиотеката Sodium, може да се види тук. В Sodium Cell са поведенията, а Stream събитията. В примера ясно може да се види разделянето на входове и изходи на компонента.
Друга широко използвана функционална абстракция са т.нар. future и promise [7], позволяващи композирането на асинхронни изчисления, извличания и трансформации на единична стойност. В JavaScript света те често биват използвани сравнително императивно, но са много по-мощни когато биват разглеждани функционално като стойност и биват композирани.
3. Разпределени системи
Голяма част от съвременните системи трябва да могат да поемат хиляди, понякога дори милиони потребители (в това число както реални хора, така и други устройства, например Internet of Things такива), а изискванията за функционалност и интерактивност към тях непрекъснато се увеличават. Един компютър не може да се справи с такова натоварване, поради което, за да остане системата отзивчива, е необходимо тя да може да бъде скалирана и разпределена на повече машини. Нещо повече, бихме очаквали тя да може автоматично да скалира нагоре при повишено натоварване, а когато то намалее броят на използваните машини отново да спадне, за да се спестят ресурси и излишни разходи. Това свойство наричаме еластичност. Казваме още, че системата реагира на натоварването.
Написано по този начин, еластичността и разпределението звучат като лесна задача, но това всъщност съвсем не е така. Напротив, нуждите от конкурентност, паралелизация и разпределеност носят със себе си най-различни проблеми и предизвикателства, произхождащи отново от времето и от особеностите на физическия свят. През 1994 г. Питър Дойч формулира 7 заблуди за разпределените системи, допълнени с 8-ма от Джеймс Гослинг [8, 9]:
- Мрежата е надеждна.
- Времето за отговор (латентност) е нулево.
- Наличен е безкраен bandwidth.
- Мрежата е сигурна.
- Топологията не се променя.
- Има само един администратор.
- Цената за пренос е нулева.
- Мрежата е хомогенна.
Причината за тях е по-обща – въпреки моделите, зад които стоят, компютрите все пак функционират в реалния свят и са повлияни от законите на физиката. В него информацията се пренася от вълни и други явления – като светлина, звук, електрически сигнали – всяко от които има нужда от време за да се разпространи в своята среда. Когато наблюдаваме звезди, намиращи се на няколко хиляди или милиони светлинни години от нас, ние получаваме информация за тяхното състояние от преди толкова години, но няма как да знаем какво е то в момента – наблюдаваната звезда може дори вече да не съществува [10]. Това е валидно и при малки разстояния. При светкавица шумът от нейното възникване стига за 1–2 секунди до хора на разстояние половин километър от нея, и за около 6 секунди на разстояние два километра. Същевременно светлината, породена от нея, достига всяка от двете групи хора за милисекунди. За да отпием от чаша топъл чай на нашето тяло се налага да обработи множество съобщения – нашите очи регистрират фотоните, отразени от чашата, за да може нашият мозък непрекъснато да обработва информацията за нейното местоположение и да изпраща правилните електрически сигнали до нашите мускули, така че да извършим необходимите действия. Разпространението на всички тези сигнали и движението на тялото отнемат време, колкото и малко да е то.
Поради тези причини, никога не знаем какво е състоянието на даден обект сега, а само какво е било в някой момент от миналото [11].
“We only know how things were, not how they are now” ― Joe Armstrong
Възможно е да пропуснем всеки един от тези сигнали – звездата може да се наблюдава само през нощта, и то ако Земята е на подходяща позиция, светкавицата може да е възникнала твърде далеч. Възможно е външно влияние да промени очакванията ни за системата – някой да вземе чая преди нас, или той да е твърде горещ и да го изпуснем.
Съвсем аналогично, сигналите в компютрите и в компютърните мрежи отнемат време за да достигнат определена дестинация. Те могат да се загубят поради интерференция, проблемен или изваден кабел, премаршрутизиране, пренатоварен хардуер, загуба на електричество и множество други причини. Могат дори да бъдат повторени и да бъдат регистрирани два или повече пъти.
Основен източник на повреди сме и самите ние, които създаваме системите, за които говорим – не съществува софтуерен разработчик, който да не пише бъгове. Бъг може да съществува и в хардуера.
Така информацията, която имаме, зависи от разстоянието ни до източника, от препятствията ни до него, от това, което околните споделят с нас (а то дори може да е погрешно), и от множество други фактори. Тези фактори са различни за всички други, поради което е невъзможно в текущия момент всички да имат еднаква информация. Това не пречи обаче, чрез обмяна на информация, всички участници (от достатъчно тесен кръг) да имат еднаква информация за преди определен момент от миналото. Колко назад във времето може да е той зависи от големината и особеностите на системата.
За програмисти реалният свят може да бъде обобщен по следния начин:
- Нещата се чупят.
- Светът е силно паралелен и информацията пътува асинхронно и с променлива латентност.
- Реалността е евентуално консистентна – липсва пълна споделена информация за настоящето.
Да разгледаме всяка от тези точки поотделно в контекста на реактивните системи.
Нещата се чупят
Тъй като повредите са неизбежни, то е необходимо да ги приемем открито в поведението на системите и в техния дизайн и програмен модел, така че те да бъдат устойчиви, т.е. системата и нейните компоненти да остават отзивчиви дори при повреди, доколкото това е възможно. Това включва реактивната система да върне съобщение за грешка, ако тя няма други алтернативи – това е много по-добре, отколкото да забави отговора си и клиента ѝ да не може да разбере дали тя работи. За да се справи с повредата, често е необходимо системата да предприеме действия за да се самопоправи – така тя реагира на тези повреди.
За да бъде една система устойчива, всеки един неѝн компонент също трябва да бъде устойчив. Тук включваме и крайните потребителски интерфейси. Потребителите трябва да бъдат уведомявани по подходящ начин за странно поведение и грешки при основната функционалност на системата. По този начин те няма да останат фрустрирани от евентуално неочаквано държание на интерфейса, а веднага ще разберат какво се случва и с по-голяма вероятност ще запазят доверието си към нас и ще се върнат отново. При повреда на допълнителни услуги, те могат да бъдат скривани и изключвани, без да се нарушава работата с основната функционалност. При изчезване на връзката към сървъра може да бъде имплементиран модел, при който всички промени се пазят локално при клиента и биват синхронизирани при нейното възстановяване (разбира се, потребителят трябва да бъде уведомен за това). Така се постига доста по-качествено изживяване за потребителите, каквато е и крайната цел на тези системи.
Светът е паралелен и асинхронен
За да обсъдим втората точка, нека първо да съпоставим синхроността и асинхроността. При синхронно изпълнение всички действия в един компонент се извършват последователно и всеки път, когато той изисква информация от външния свят, той не преминава към следващо действие, докато тя не бъде получена. Това означава, че компонентът става зависим от някой външен компонент и напълно изолиран от останалата част от външния свят – нито може да реагира на друга информация, освен поисканата, нито да изпрати навън нова. При асинхронно изпълнение компонентът не е обвързван с изчакване на информацията и е свободен да извършва други действия.
Да разгледаме поведението на един човек. Въпреки че асинхронно се случват най-различни неща в тялото ни, на едно по-високо и по-опростено ниво ние предпочитаме да мислим за тях синхронно и постъпково, тъй като това е много по-лесно. Това важи най-вече за действия, които се изпълняват за кратко време, и които имат малък шанс да се провалят или бъдат прекъснати – не бихме се справили да асимилираме цялата информация, ако извършваме множество от тях наведнъж. Когато обаче чакаме нещо продължително, ние, естествено, предпочитаме да свършим и други неща през това време – например докато асинхронно си пътуваме можем да почетем книга и да се насладим на топла напитка. Разбира се, човешкият разум е много по-сложен, същевременно и рядко е строго синхронен, но това е опростено обобщение.
Аналогично, подходящият режим за един програмен компонент би зависел от балансирането на множество фактори:
- за колко време пристигат отговорите на заявките му и какъв е шансът изчисляването и изпращането на тези отговори да се провали;
- може ли той да извърши нещо друго междувременно – изчисление, изпращане на съобщение или получаване на такова;
- как би се отразило синхронното му блокиране върху ресурсите на машината;
- каква е цената на избрания механизъм за асинхронната комуникация срещу избрания за синхронна.
Нека да разгледаме всеки един от тях.
Синхронната комуникация е по-сложна за реализация и изисква специални механизми, като например канал с тактов сигнал. Асинхронната предаване на данни е по-просто. Често обаче данните по него биват съпътствани с контролна информация, поради което, при пълно натоварване на канала, синхронната комуникация позволява по-добра пропускливост. Така например, при текущите операционни системи, синхронния вход и изход пропуска повече данни от асинхронен такъв, реализиран чрез шаблоните reactor или proactor. Когато обаче системата има множество паралелни клиенти или такива, непредаващи си чак толкова много данни, по-важни се оказват другите фактори.
Таблицата по-долу показва времената за отговор на някои често срещани операции [12].
| Дейност | Латентност (ns) | Латентност (скалирана) |
|---|---|---|
| Достъп до L1 кеш | 0,5 | 10 ms |
| Грешно предричане за разклонение | 5 | 100 ms |
| Достъп до L2 кеш | 7 | 140 ms |
| Заключване/отключване на мютекс | 25 | 500 ms |
| Достъп до главната памет | 100 | 2 секунди |
| Компресия на 1KB със Zippy | 3 000 | 1 минута |
| Прочитане на 4KB от SSD | 150 000 | 50 минути |
| Round trip в същия datacenter | 500 000 | 2,78 часа |
| Пакет от Канада до Нидерландия и обратно | 150 000 000 | 34,7 дни |
За да можем по-лесно да си представим тези стойности, към таблицата добавяме и колона, в която времената са скалирани 20 000 пъти, така че да се доближат до времената, с които ние хората мислим. Нормално, време от няколко стотин милисекунди до няколко секунди е такова, в което бихме могли съзнателно да реагираме на събитие, случващо се асинхронно [13]. При време, по-голямо от няколко секунди и особено минути, едва ли ще издържим само да чакаме, без да свършим и нещо друго.
Основната част от работата на един процесор в съвременните архитектури е да извършва последователни/постъпкови изчисления и да разменя данни между своите регистри и кеш памет. Както се вижда от таблицата, тези операции са сравнително мигновени. Рядко съществува нещо друго, което да се извърши между тях за по-малко време. Те са с изключително малка вероятност за грешка, а при възникване на такава не съществува надежден механизъм под наш контрол, който да може да я открие и поправи. За тези императивни операции синхронния модел е най-подходящ.
Включвайки все повече участници от заобикалящия свят обаче нещата започват да се променят. Синхронизацията между тях винаги изисква специфични механизми, които носят със себе си по-голяма сложност. Така, боравенето с мютекси за синхронизация между различни нишки и процесорни ядра е значително по-сложна задача и, за да избегнем проблеми с производителността, е необходимо достъпът до тях в нашите програми да бъде ограничен до минимум. Това обаче е много по-трудно да бъде направено за достъпа до главната памет – част от основните операции на всяка една програма. Той е значително по-бавен – „2 секунди“ е време, в което всеки от нас може съзнателно да измисли или направи нещо важно, да не говорим, ако ги получаваме за всяко четене или писане в паметта. За да се справят с този проблем, съвременните процесорни архитектури използват няколко похвата, които тук ще назовем с термина „магия“. Основният от тях е механизмът с няколко нива на кешове. Допълващ го е т. нар. „принцип на референтна локалност“, който гласи, че наскоро използвани данни и данни, които се намират близко до тях в паметта, е доста вероятно да бъдат реферирани от следващите инструкции. Затова системата запазва в кеша достъпените клетки от паметта и асинхронно извлича и следващите. Тази „магия“ позволява запазването на сравнително добра производителност на синхронния модел, но все повече се оказва недостатъчна в сложните съвременните приложения и все по-често процесорите не работят на пълен капацитет, а прекарват времето си в изчакване на клетки от паметта.
Последните редове показват времето за отговор при комуникация с по-външни компоненти – такива са устройства за съхранение на данни, периферни устройства, комуникация в локалната мрежа и по Интернет и други. Това всъщност са основните източници на асинхронни събития за софтуерните реактивни системи. Времената при тях са многократно по-големи, а повредите и изгубените съобщения много по-вероятни, на практика сигурни. Едва ли някой от нас би чакал минути, камо ли часове или дни, без да свърши нещо друго през това време. Или не би помръднал никога, ако очакваният отговор се изгуби. Доста често обаче именно по този начин програмираме нашите софтуерни системи – използваме един и същи програмен подход за всяко едно от възможните действия в таблицата, въпреки че по природа те са различни.
Обичаме да програмираме по начина, по който програмираме трансформиращите системи. Това е напълно естествено, тъй като при тях проявата на времето от външния свят липсва. Комуникацията им навън се извършва синхронно, с най-много един външен компонент в даден момент, и то когато изрично поискат това. Много от имплементациите на уеб и други сървъри са реактивни само в момента на първоначално получаване на заявка, при което тя бива предавана за обработка към някоя нишка в системата, която до края на обработката работи единствено в трансформиращ режим и комуникира с външни компоненти единствено чрез синхронни и блокиращи функции. Този подход за отдалечена комуникация често бива наричан Remote Procedure Calls (RPC). Ако и двата края на комуникационния канал го използват, то можем да кажем, че RPC създава зависимост между две нишки, намиращи се на две различни машини – първата става напълно зависима от времето за изчисление на втората, от евентуалните повреди, които могат да възникнат при нея, и от комуникационния канал между тях.
Публикацията „A Note on Distributed Computing“ на Джим Уалдо [14] разглежда проблемите на този подход в много по-големи подробности – неочаквана латентност и задържане на ресурси (нишки, памет и други), скрито копиране на памет, частични повреди и получаване на съобщения за грешка, за които блокираният компонент няма какво да направи, и други. Поради тези причини авторите на публикацията излагат твърдението, че всички отдалечени извиквания трябва да бъдат третирани специално.
Нишките в операционните системи са сравнително скъп ресурс – те стартират бавно, заемат известно количество памет, а превключването между нишки е скъпо. За избягване на бавното стартиране обикновено се използва pool от няколко стотин или хиляди нишки, готови да поемат работа. Превключването между нишките, особено при такъв голям брой, е проблем, тъй като то изисква system call към ядрото на операционната система, презареждане на голямо количество регистри в процесора, изпразване на неговия конвейер и, най-вече, нарушаване на неговата „магия“ – малка част от това, което е заредено в кеша, би било използвано от новата нишка. Всяко RPC води до минимум две превключвания.
Най-големият проблем на нишките и RPC обаче е концептуален [15] – те предоставят сложен и силно податлив на грешки модел за конкурентност и правят извършването на няколко паралелни задачи трудно и некомпозитно.
За реактивните системи са ни необходими конкурентни модели, които да изразяват особеностите на асинхронния свят по безопасен начин. За запазване на отзивчивостта се нуждаем от програмен модел, при който да можем да реагираме асинхронно и без блокиране на всяко важно външно събитие. При разпределени системи тези събития са получаването и изпращането на съобщения. Затова разпределените реактивни системи трябва да бъдат ориентирани около асинхронни съобщения и да реагират на тези съобщения.
Явното приемане на асинхронността и съобщенията в програмния модел носи със себе си множество други ползи:
- Намалява се зависимостта между компонентите – получателят вече може сам да избере как, кога и дали да обработи съобщението. Изпращащият компонент не е блокиран в очакване на отговор и е свободен да извърши други действия.
- Паралилизирането на изчисления и извличане на данни става лесно, чрез изпращане на няколко съобщения наведнъж, резултатите от които могат да бъдат комбинирани в последствие.
- Съобщенията се превръщат в явни обекти, които можем да управляваме – можем да ги поставяме в опашки, да ги съхраняваме, да ги трансформираме, филтрираме и т.н. – също както всеки един друг обект.
- Съобщенията ни позволяват създаването на по-сложни комуникационни протоколи между компонентите, при които да приложим похвати като динамична маршрутизация, балансиране на натовареността, репликация и други.
- Асинхронната комуникация позволява лесното образуване на реалновремеви потоци от съобщения до други компоненти.
- За управление на възникналите грешки и повреди можем да използваме съобщения с информация за тях, които да разпространяваме по същата инфраструктура, както всяко едно друго съобщение.
Ще разгледаме някои от ползите допълнително по-надолу.
За максимално натоварване на процесора, реактивните приложения обикновено използват pool от малък брой нишки (сравним с броя на процесорните ядра), които не блокират, а обработват идващите съобщения. Точната имплементация зависи от избрания механизъм и/или конкурентен модел.
Реактивни свойства
Така по естествен начин стигнахме до четирите основни свойства на разпределените реактивни системи, описани през 2013-та година в манифеста на реактивните системи [16]:
- отзивчивост – реагиращи на външни стимули;
- еластичност – реагиращи на натоварване;
- устойчивост – реагиращи на повреди;
- ориентираност около съобщения – реагиращи на асинхронни съобщения.
Следващата фигура изобразява връзките между тях:

Свойствата, намиращи се по-надолу, подпомагат тези по-нагоре, за да може да бъде постигната основната цел на реактивните системи – отзивчивостта.
Важно е да се отбележи, че със сложността на съвременните компютри – най-вече наличието на множество процесорни ядра, които си говорят помежду си по определени механизми – всички тези принципи са приложими и на една локална машина.
Как обаче да разпространяваме информацията за възникналите събития в разпределените системи при тези принципи? Всяко събитие описва нещо случило се в миналото – факт, който е невъзможно да бъде променен. Начинът за разпространение на факти са съобщенията. Важно е да се прави разлика между събитие и съобщение – събитийните съобщения носят информация за определено събитие и, като всяко друго съобщение, те могат да бъдат трансформирани и филтрирани. Но самият факт, че събитието се е случило е неизменим. Едно събитие може да породи няколко съобщения, които да се разпространят по различен начин – за възникването на светкавица можем да разберем от нейната светлина, специфичен звук или виждайки последствията от нея по-късно. Получаването и на светлинните и на звуковите сигнали би ни позволило да определим разстоянието ѝ до нас.
Реалността е евентуално консистентна
Както видяхме, паралелността и асинхронността не позволяват всички участници в една система да имат една и съща информация във всеки един момент. Единственият начин да се постигне това е при всяко ново събитие тази система да бъде паузирана (да бъде „спрян“ нейният свят), така че тя да не може да генерира нови събития, докато текущото не бъде разпространено – т.е. да се премахне паралелността. Освен че с това губим възможността за скалируемост в тези моменти, такъв механизъм е вид синхронизация – изисква специални средства и протоколи на комуникация. Той допълнително се усложнява от възможностите за частични повреди.
Има различни трудове, които разглеждат проблема подробно и теоретично – като CAP теоремата или по-силният от нея резултат FLP [11]. CAP ни казва, че можем да изберем само две свойства от следните три: строга консистентност, наличност на системата във всеки един момент и толерантност към частични повреди в системата. Реактивните системи трябва да са устойчиви на такива повреди, затова изборът ни остава между първите две. При строгата консистентност обаче се губи скалируемостта, ако е приложена за твърде голяма част от системата (последствията от това ще анализираме по-надолу, когато представим универсалния закон на скалируемостта).
Възниква въпросът дали наистина имаме нужда от строга консистентност в нашите програми, както сме свикнали от релационните бази от данни. Целта на софтуера е да моделира процеси от реалния свят, често за решаване на някой бизнес проблем. Но светът винаги е работил без проблеми с евентуална консистентност. Дори най-често даваният пример за консистентност – трансфер на парична сума между две банкови сметки – не е съвсем такъв в банковия свят. Банката обикновено веднага отбелязва нашите пари като неналични в нашата сметка, но появата им в другата сметка може да отнеме от няколко секунди до дори няколко часа, ако е в друга банка. Поради различни проблеми в сметката на получателя, е възможно той да не може да получи сумата, поради което банката ще ни върне парите и ще ни уведоми, че е възникнал проблем. Тоест банките и другите бизнеси са приели особеностите на заобикалящия ги свят в своя начин на работа, и оперират без проблеми в него, създавайки подходящи механизми, в зависимост от своя домейн – в случая дългоживеещи парични транзакции.
При разпределените системи съществува популярен шаблон, наречен Saga [17], който ни позволява да изпълняваме дългоживеещи транзакции, които не са атомарни. При него работата се разбива на подтранзакции, които се изпълняват последователно, като на всяка от тях се съпоставя и компенсираща подтранзакция, която семантично да премахне действията на правата, ако нещо в процеса се повреди. Разбира се, не винаги някое действие може да бъде премахнато, така че да изглежда, че никога не се е случвало, но често в такива ситуации компенсиращата транзакция може да се изразява в писмо за възникнат проблем или обаждане по телефона.
Разбира се, строгата консистентност остава фундаментална в нашите приложения, като обикновено е силно приложима в локален мащаб. Например Domain-Driven Design дефинира понятието агрегат, което определя транзакционни граници, но разпространението на информация извън него често е с евентуална консистентност.
4. Постигане на реактивните свойства
Темите, свързани с това как да предадем описаните свойства на софтуера, който създаваме, са многобройни и дълбоки. Реално с това се занимават голяма част от изследванията в сферата на компютърните науки още от десетилетия, а през последните години изключително активно се разработват все повече нови решения, базирани на тези изследвания. Най-подходящите архитектура и подходи зависят от целите и изискванията към самата система и често са въпрос на баланс между различни характеристики и очаквания.
Нека все пак да разгледаме някои основни принципи, които са сравнително универсални. Асинхронната комуникация чрез съобщения подпомага всяко от останалите свойства, затова тя ще бъде анализирана при тях.
Еластичност
Скалируемостта на компонентите в една софтуерна система зависи от това доколко изчисленията в нея могат да бъдат паралелизирани.
Законът на Амдал е един от най-основните принципи, даващ ни оценка на този фактор [18]. Нека T(1) е времето, което е необходимо за извършване на определено изчисление без паралелизация, само от един процес, а T(n) – времето, необходимо на n паралелни процеса. Тогава увеличението на производителността S(n), което получаваме от n паралелни процеса, ще бъде равно на T(1)/T(n). Нека σ ∈ [0, 1] е частта от изчислението, която не може да бъде паралелизирана. Това означава, че в тази част процесите се синхронизират помежду си и само един от тях извършва ефективна работа, докато останалите изчакват. Законът на Амдал изразява T(n) по следния начин: T(n) = σT(1) + (1 - σ)T(1)/n – тоест сума на времето, прекарано в синхронизация, при което имаме ефективно един активен процес, и на това в паралелизация, при което всички процеси са активни. Ако заместим T(n) в дефиницията на S(n), след математически преобразувания стигаме и до самата формула на закона:

Следващата графика описва как параметрите влияят на скалируемостта според Амдал:

Виждаме, че при 50% синхронна част изчислението не може да бъде паралелизирано повече от два пъти, като този максимум се постига чак при 16 паралелни процеса. Дори при едва 5% синхронна част, след десетократно подобрение на производителността ползата от повече процеси започва рязко да спада, а максимумът подобрение е 20 пъти, което се достига при нереалистично огромен брой процеси.
Всичко това означава, че за да имаме истински скалируема система, то трябва да сведем непаралелизуемите ѝ части до минимум. Как да се направи това зависи от природата на самия проблем, който се решава.
Важно е да се отбележи, че голяма част от софтуерните системи нямат нужда от изключително голяма скалируемост. Ако е трудно да се създаде свръх скалируем дизайн, то опитът за това при тях би бил прибързана оптимизация и водещ до излишна сложност. Винаги трябва да се водим от изискванията към системата.
Законът на Амдал не отчита една от най-важните особености на физическия свят, която обсъдихме – разпространението на информация и синхронизацията между различните участници отнема време. Затова Нийл Гънтър допълва формулата с още един важен параметър, който ще означим с λ – коефициент, отразяващ времето, необходимо за постигане на съгласуваност между процесите. Тогава законът придобива следния вид:

Тази формулировка бива наречена универсален закон на скалируемостта [19]. Графиката по-долу прави съпоставяне между закона на Амдал и този на Гънтър.
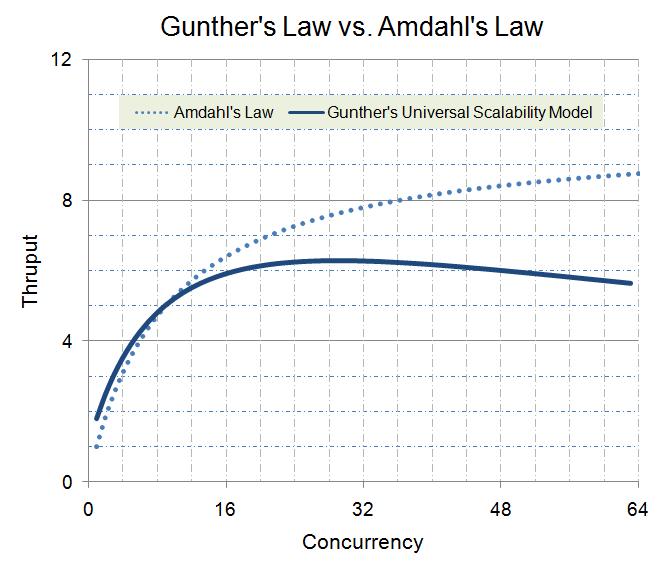
Виждаме, че при наличие на синхронни части, след определена граница добавянето на процеси и изчислителни единици не само спира да води до увеличаване на производителността, но нещо повече – тя започва да намалява.
Скалируемостта е необходимо условие за постигане на еластичност, а най-естественият начин за това е чрез репликиране на услуги и компоненти. Използването на съобщения ни позволява то да стане лесно, чрез подход, наречен location transparancy (прозрачност на местоположението). При него всяка инстанция на компонент получава адрес, като изпращането на съобщение до даден адрес изглежда еднакво, независимо от това дали компонента е локален или отдалечен. Така следваме препоръката на Уалдо да третираме компонентите, които могат да бъдат разпределени, по специален начин в нашия програмен код. Тези адреси могат да бъда изпращани като съобщения на всеки друг компонент, така че различните компоненти динамично да научават един за друг. Свързването с реплики обикновено се осъществява чрез маршрутизатори, които препредават съобщението и адреса на изпращача към някоя реплика. Изпращачът не се интересува от това къде се намира репликата.
Остава въпросът как да определим необходимия брой реплики, които да поемат текущото натоварване. Фундаментален в разпределените системи е законът на Литъл [20]:

В него λ отразява заявките за единица време (брой заявки в секунда), а W средното време за обработка на една заявка (секунди). Тогава L е минималният брой реплики, от които се нуждаем, така че системата да може да обработва достатъчно бързо идващите заявки и опашките, които използваме, да не се препълват. Подходящ компонент от системата може да следи за тези характеристики и да добавя и премахва реплики, когато това е необходимо.
Алтернативно може да следим използването на ресурси на различните машини – памет, натоварване на процесора, натоварване на мрежата и други – и да маршрутизираме и надигаме и сваляме реплики в зависимост от техните стойности. За определяне на границите обаче е необходимо да се направят подходящи измервания.
Ще отбележим, че е важно опашките, които използваме за съхранение на тези съобщения, да са ограничени. В противен случай рискуваме при натоварване и недостатъчно бързо вдигане на реплика паметта на системата да се запълни, което ще доведе до пагубен ефект и откази в системата в критичен момент. При получаване на съобщение, за което няма място, може да изберем различни подходи, в зависимост от типа на системата – като да отхвърлим новото съобщение, тъй като няма как да го обработим достатъчно бързо, или, в случай на реалновремева система, да отхвърлим най-старото в опашката, тъй като най-вероятно вече не е толкова релевантно, и в нея да поставим новото. При всеки от случаите е добре веднага да изпратим обратно съобщение за грешка в отговор на отхвърленото съобщение, за да може клиентите на компонента бързо да разберат, че има проблем. С това навлязохме в темата за постигане на устойчивост…
Устойчивост
Най-основните правила за постигане на устойчивост, особено при големи системи, са репликиране на услугите и данните и изолацията им едни от други. Очевидно репликирането позволява, ако някой компонент се повреди, някоя негова реплика да поеме ролята му. Изолацията е важна, защото много проблеми имат свойството да се разпространяват в системата. Темата за каскадиращи проблеми ще засегнем малко по-надолу, но в локален мащаб един добър пример е спирането на захранването на сградата, в която се помещават нашите сървъри, или проблеми с мрежата в целия град. Затова при изключително големи системи, услужващи потребители от цели страни или целия свят, е изключително важно изолацията и репликацията да стават на по-големи разстояния. Използването на location transparancy също помага за постигането на това.
Няколко пъти вече говорихме за значението на това реактивните компоненти да изпращат съобщение за грешка възможно най-рано. Основната полза е, че клиентските компоненти могат да реагират на тези съобщения. Когато разберат за проблем, те могат да опитат да извлекат нужната им информация от по-бавна или по-неточна услуга, да вземат по-стари, но полезни данни от някой кеш, самите те да върнат грешка по-бързо или нещо друго, зависещо от домейна и системата. А благодарение на своевременни съобщения за грешки, те ще знаят достатъчно рано да се отнасят по-предпазливо към проблемния компонент.
Интересен феномен са каскадиращите повреди – когато проблем в един компонент води до проблем в другите части на системата. Например повреда поради пренатоварване води до по-голямо натоварване на останалите реплики, поради което те самите могат да бъдат пренатоварени. Като друг пример ще разгледаме системи с RPC. Обикновено при RPC липсва механизъм, който да следи състоянието на използваните услуги. Ако клиентски компонент използва RPC към натоварен или повреден компонент, всяка нова заявка ще доведе до продължително задържане на ресурсите на клиента, докато заявката не таймаутне, а самият клиент ще може да поеме ограничен брой заявки от други части на системата, тъй като нишките му са заети в чакане. Така, поради лошо управление на ресурси, един проблем може да се разпространи в цялата система.
В допълнение, ако един компонент е пренатоварен, то непрекъснато изпращане на заявки и повторения на заявки към него със сигурност няма да му помогнат.
Поради тези причини реактивните компоненти трябва, от една страна, да ограничават натоварването, което могат да поемат, а от друга, да предпазват компонентите и услугите, които те самите ползват, и да не позволят повреда в тези услуги да доведе до проблеми в самите тях. Подходящ механизъм за първото, както вече споменахме, са ограничените опашки. За второто ще разгледаме две решения.
Едното е механизъм, вдъхновен от електроинженерството, наречен верижен прекъсвач (circuit breaker):

Начинът му на работа много прилича на този на един електрически бушон. Прекъсвачът се поставя пред връзката с външния компонент. В началото той се намира в затворено състояние и всички съобщения през него минават успешно. Но когато започне да забелязва проблеми – като забавени или непристигащи до определено време отговори, прекъсвачът приема, че има проблем с външната система и преминава в отворено състояние, при което нито едно съобщение не минава успешно, а веднага се връща съобщение за грешка. След известно време той минава в полуотворено състояние, с надеждата, че външната система се е възстановила. В това състояние се пропускат само по няколко съобщения. Ако бъдат получени успешни отговори за тях, то прекъсвачът преминава обратно към затворено състояние. Той може да вземе и допълнителни мерки, ако това се повтори няколко пъти.
Другото решение е прост принцип – при повреда опитите за повторна връзка не трябва да стават едновременно. Това може да доведе до ново падане на компонента, тъй като би значело, че всички негови клиенти се свързват с него в един и същи момент. Начинът за справяне с това е добавяне на случайна стойност към времето между опитите за повторна връзка, и постепенно увеличаване на това време при постоянна загуба на връзка. Доста често виждаме този похват в потребителските интерфейси на големи системи, които ни предоставят и бутон, чрез който веднага да опитаме осъществяването на нова връзка.
Накрая ще разгледаме механизъм, който позволява на реактивните системи да се лекуват. Този механизъм се нарича supervision (наблюдение) и е най-добре изследван от Джо Армстронг, създател на езика Erlang, в неговата дисертация „Making Reliable Distributed Systems in the Presence of Software Errors“ [21]. Идеята е за всеки компонент да отговаря специален компонент, наречен supervisor, който се намира сравнително локално и се грижи за неща като:
- поправяне на (познати и непознати) повреди;
- скалиране нагоре и надолу, в зависимост от натоварването;
- откриване на странно поведение и др.
Обикновено самите supervisor-и също си имат свои supervisor-и. При такъв подход компонентите образуват дървовидна структура, а инстанции по листата на дървото са тези, които вършат най-конкретната работа.
Както споменахме по-рано, клиентът няма как обработи евентуално изключение за повреда на използвания от него компонент, тъй като обикновено няма какво да предприеме за поправянето му. Много по-смислено е такива грешки да бъдат обработвани от supervisor-ите, тъй като те са тези, които отговарят за компонентите, и могат да предприемат локални действия. Ако повредите зачестят, или ако са от непознат за тях тип, те могат да предприемат и познатото ни на всички ултимативно решение:

Рестартирането на част от системата, така че тя да излезе от някое лошо състояние, в което е попаднала, често се оказва изключително ефективно. Не винаги supervisor-ът успява да реши проблема, поради което се налага ескалиране на грешките към неговия supervisor, който да опита подобни подходи върху по-голяма част от системата.
Отзивчивост
Както видяхме, всички останали принципи и свойства подпомагат отзивчивостта.
Вече разгледахме някои начини за намаляване на времето за отговор и съответно увеличаване на отзивчивостта. Добър подход е да поставяме ограничение и таймаут на нашите заявки – ако той изтече, то връщаме грешка. Определянето на подходящ таймаут е по-сложен въпрос, който зависи от това доколко приложението може да си позволи преждевременно прекъсване в някои по-редки случаи. Обикновено е съпътствано с множество измервания и експерименти за установяване на подходящите параметри. Дори обаче да определим по-голямо време от оптималното, за да постигнем реактивност е необходимо да го има.
Друг фундаментален подход е паралелизирането на заявки, което при асинхронни съобщения и асинхронни модели е изключително лесно. Например този код, извличаш последователно данни от някоя база:
val user = users.find(userId)
val product = products.find(productId)
dispatchOrder(product, user.name, user.address)може да се направи паралелизуем изключително лесно чрез конкурентни примитиви, като future-ите:
val userFuture: Future[User] = users.find(userId)
val productFuture: Future[Product] = products.find(productId)
for {
user <- userFuture
product <- productFuture
} yield dispatchOrder(product, user.name, user.address)Тук двете заявки ще бъдат изпратени едновременно, а когато техните резултати пристигнат, напълно асинхронно ще бъде направена поръчка по тях.
5. Как да се справим с всичко това?
Основната цел на потребителската група е да обсъдим различни и разнообразни начини за това.
Досега вече споменахме повечето технологични теми, които изредихме в началото. Тук ще разгледаме и останалите и това как те ни подпомагат при изграждането на реактивни системи.
Конкурентни модели
Видяхме, че конкурентния модел на нишките е труден за менажиране. Всъщност съществуват множество други конкурентни модели, които са много по-разбираеми и предпазващи ни от грешки, и които са изключително подходящи за различни аспекти на реактивните системи, като всеки от тях е най-изразителен в различни типове задачи. Такива са вече споменатите future-и и promise-и (реализирани в много езици), актьорският модел (в Erlang и библиотеки като Akka), Communicating Sequential Processes (Go, clojure.async), Software Transactional Memory (Clojure и други реализации), различни подходи за неблокираща конкурентност и неблокиращ IO, реактивните потоци, които ще разгледаме по-надолу, и други.
Тук няма да ги описваме подробно – всеки от тях е дълбока тема. Интересно е, че много от тях се развиват още от 70-те години.
Ше отбележим нещо интересно за актьорския модел – той много прилича на оригиналната идея за обектно-ориентирано програмиране на Алан Кей [22]:
“I thought of objects being like biological cells and/or individual computers on a network, only able to communicate with messages… OOP to me means only messaging, local retention and protection and hiding of state-process, and extreme late-binding of all things.” ― Alan Kay
В оригиналната си идея ООП всъщност е реактивна концепция и е именно имплементация на някои от принципите, за които говорихме.
Функционално програмиране
Всъщност вече описахме част от предимствата на функционалното програмиране в секцията за локални системи. Реално функционалните принципи са дори още по-приложими и полезни при разпределените системи поради сложността и природата на тези системи и поради това че те, също като функциите, работят с и си комуникират чрез неизменяеми факти. Функционалното програмиране ни позволява да направим програмирането им доста по-възможно и да контролираме част от тази сложност.
Domain-Driven Design
Domain-Driven Design (DDD) е подход, който се в състои в базирането на нашия дизайн, код и комуникация помежду ни върху модел на домейна, в който е софтуера, който реализираме. DDD ни позволява да попием от годините мъдрост, през които този домейн се е развивал и изчиствал спрямо особеностите на реалния свят (а това е ставало и в среда на евентуална консистентност), да вземем неговите термини и правила и директно да ги използваме в нашия дизайн. Това го прави много по-богат, лесен за разработка и много по-лесно можем да изказваме твърдения и да разсъждаваме за него.
Докато нашият продукт и моделът еволюират, може да се окаже, че моделът е станал твърде голям. Освен това различните част на софтуера могат да се нуждаят от различен поглед върху домейна, т.е. различен модел. В тези случаи DDD проповядва разделянето на домейна на по-малки части, наречени ограничени контексти (bounded contexts), които по смислен начин съществуват самостоятелно. Границите на тези ограничени контексти са естествени граници, около които можем да образуваме разпределени микросървиси. DDD също така ни предоставя важни техники за моделиране на комуникацията и зависимостите между различни ограничени контексти.
Нещо интересно, което вече отбелязахме, е понятието агрегат, което DDD дефинира в един ограничен контекст. То ни позволява при моделиране да ограничаваме строгата консистентност до малки части на нашия софтуер.
Съхранение и моделиране на данните
Разпределените системи носят със себе си доста разнообразни изисквания за съхранение на своите данни. Затова и в последните години се наблюдава огромно разнообразие на различни разпределени системи за управление на бази от данни, които имплементират различни гаранции около свойствата, които разгледахме. Реално изборът на правилния подход се оказва все по-труден.
Публикацията „Immutability Changes Everything“ [3], която вече споменахме, разглежда как съхраняването на неизменяеми данни може да ни разкрие много нови възможности. Интересен метод е т нар. event sourcing, при който, вместо текущо състояние, съхраняваме неизменяемите факти и събития, довели до това състояние. Така ние съхраняваме реалните причини, довели ни до този момент. Това ни позволява да се връщаме назад във времето и да извличаме допълнителна информация от старите данни, както и да поправяме грешки, които може да са възникнали поради бъгове. Допълнително, фактите са естественият начин за комуникация между компонентите на разпределените системи, те се съхраняват много лесно – чрез добавяне, и поради това че носят информация за събитието, водещо до промяна на състояние, а не самото състояние, позволяват по-лесно достигане на консистентност.
Event sourcing-ът много добре се комбинира с подход, алтернативен на CRUD, наречен Command Query Responsibility Segregation (CQRS) [23]. Той разделя командите (обновленията) от заявките за данни. Командите съвпадат с присъщи за домейна глаголи. Те са естествен източник на събития за event sourcing. Отделянето на заявките ни позволява да образуваме множество различни компоненти, отговарящи за заявки на различни данни, породени от тези команди – тоест можем да оптимизираме за различни нужди на приложението (в контраст с релационните бази и CRUD, където често запитваме директно текущото състояние, в което съхраняваме данните си). Всеки от тези компоненти може да съхранява информацията си в подходяща за него база, включително релационна.
Много често дизайнът на реактивните системи, особено когато се използва CQRS, бива съпътстван от специални сесии, наречени event storming. Кевин Уебър предлага добро описание на това какво представляват те. Тези сесии подпомагат именно постигането на DDD и използването на реалистичен модел в нашите програми.
Реактивни потоци
Много подходящ модел за реактивните системи и за системи, генериращи данни в реално време, е поточният. Същевременно се появяват най-различни имплементации на потоци. Затова преди няколко години се организира инициатива, целяща да дефинира какво е това реактивен поток, както и да предостави програмен интерфейс, чрез който различни имплементации да могат да говорят помежду си. За момента този интерфейс е наличен само за JVM и ще бъде включен в стандартната библиотека на Java 9.
По-интересни са възможностите, които тези потоци предоставят. Както видяхме от секцията за локални системи, поточният дизайн значително улеснява разпространението на данни в системата и композирането на отделни нейни части. Вече съществуват имплементации за различните бази от данни, messaging решения, системи за обработка на големи данни, както и имплементации с по-общо предназначение, каквито са Akka Streams, Project Reactor, RxJava, имплементацията на Iteratees в Play Framework, Swave и други. Благодарение на тези спецификация можем да композираме всички тези компоненти изключително лесно.
Бележито свойство на реактивните потоци е т. нар. backpressure. Както споменахме, трябва да държим идващите съобщения, които изискват повече обработка, в ограничени опашки, за да може паметта на системата да не бъде препълнена. Backpressure е типичен реактивен подход, при който, в допълнение на ограничените опашки, компонентите комуникират назад в потока колко съобщения биха могли да поемат, а източниците на съобщения в никой момент не изпращат повече съобщения, от колкото им е комуникирано. Така допълнително си спестяваме изпращането на съобщения, които не могат да бъдат обработени, а с това и допълнително натоварване на комуникационните канали в критичен момент. Това спомага за по-добра устойчивост.
Интересно е, че протоколът TCP има вграден механизъм за backpressure. Реактивните потоци ни позволяват да се възползваме напълно от него.
6. В заключение
В днешно време твърде често технологични решения биват базирани на тенденции, вместо на обосновани оценки. Жертва на тенденциозно преувеличение е и реактивността – тя често бива разбирана като нещо ново, което магически ще промени света на разработката на софтуер, или като поредната buzzword, чиито концепции са безсмислени. Както видяхме обаче всички тези крайности са погрешни.
Всъщност повечето от съвременните софтуерни системи притежават в някаква степен реактивни свойства. Постигането на изцяло реактивен софтуер, който да работи в различните възможни ситуации, е трудно. Тук на помощ идват всички изброени в началото теми, които обикновено са реалният предмет на текстове, лекции, дискусии и събития за реактивни системи. „Реактивност“ е просто дума, която дефинира крайната цел.
Правилното проектиране на реактивни системи е свързано с много работа, при която трябва да се следват основните принципи, които изложихме тук. Всички ние „стъпваме върху раменете на гиганти“, които развиват областта от десетилетия.
Водещият фактор при дизайн и имплементация на софтуерни системи трябва да са техните изисквания [24].
Референции
- [1] David Harel and Amir Pnueli, On the Development of Reactive Systems
- [2] Sean Parent, A Possible Future of Software Development
- [3] Pat Helland, Immutability Changes Everything
- [4] Примерът е вдъхновен от Evan Czaplicki, Functional Reactive Programming in Elm
- [5] Conal Elliott and Paul Hudak, Functional Reactive Animation
- [6] Conal Elliott, Push-Pull Functional Reactive Programming
- [7] Henry G. Baker, Jr. and Carl Hewitt, The Incremental Garbage Collection of Processes
- [8] Peter Deutsch, The Eight Fallacies of Distributed Computing
- [9] Peter Bailis and Kyle Kingsbury, The Network is Reliable: An informal survey of real-world communications failures
- [10] Joe Armstrong, The Mess We’re In, Causality and Simultaneity
- [11] Justin Sheehy, There is No Now
- [12] Jonas Bonér, Latency Numbers Every Programmer Should Know
- [13] How Fast Your Brain Reacts To Stimuli
- [14] Jim Waldo et al, A Note on Distributed Computing
- [15] Edward Lee, The Problem with Threads
- [16] Reactive Manifesto
- [17] Caitie McCaffrey, Applying the Saga Pattern
- [18] Gene Amdahl, Validity of the single processor approach to achieving large scale computing capabilities
- [19] Neil Gunther, A Simple Capacity Model of Massively Parallel Transaction System
- [20] John Little, A Proof for the Queuing Formula: L = λW
- [21] Joe Armstrong, Making Reliable Distributed Systems in the Presence of Software Errors
- [22] Dr. Alan Kay on the Meaning of “Object-Oriented Programming”
- [23] Greg Young CQRS Documents
- [24] Martin Thompson and Mac Slocum, Design pressures lead to better code and better outcomes